Ranking: objectives and metrics
Pairwise metrics
Pairwise metrics use special labeled information — pairs of dataset objects where one object is considered the winner
and the other is considered the loser
. This information might be not exhaustive (not all possible pairs of objects are labeled in such a way). It is also possible to specify the weight for each pair.
If GroupId is specified, then all pairs must have both members from the same group if this dataset is used in pairwise modes.
Read more about GroupId
The identifier of the object's group. An arbitrary string, possibly representing an integer.
If the labeled pairs data is not specified for the dataset, then pairs are generated automatically in each group using per-object label values (labels must be specified and must be numerical). The object with a greater label value in the pair is considered the winner
.
The following variables are used in formulas of the described pairwise metrics:
- is the positive object in the pair.
- is the negative object in the pair.
See all common variables in Variables used in formulas.
PairLogit
Note
The object weights are not used to calculate and optimize the value of this metric. The weights of object pairs are used instead.
Usage information See more.
User-defined parameters
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
max_pairs
The maximum number of generated pairs in each group. Takes effect if no pairs are given and therefore are generated without repetition.
Default: All possible pairs are generated in each group
PairLogitPairwise
This metric may give more accurate results on large datasets compared to PairLogit but it is calculated significantly slower.
This technique is described in the Winning The Transfer Learning Track of Yahoo!’s Learning To Rank Challenge with YetiRank paper.
Usage information See more.
Note
The object weights are not used to calculate and optimize the value of this metric. The weights of object pairs are used instead.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
max_pairs
The maximum number of generated pairs in each group. Takes effect if no pairs are given and therefore are generated without repetition.
Default: All possible pairs are generated in each group
PairAccuracy
Note
The object weights are not used to calculate the value of this metric. The weights of object pairs are used instead.
Can't be used for optimization. See more.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
Groupwise metrics
YetiRank
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
An approximation of ranking metrics (such as NDCG and PFound). Allows to use ranking metrics for optimization.
The value of this metric can not be calculated. The metric that is written to output data if YetiRank is optimized depends on the range of all N target values () of the dataset:
- — PFound
- — NDCG
This metric gives less accurate results on big datasets compared to YetiRankPairwise but it is significantly faster.
Note
The object weights are not used to optimize this metric. The group weights are used instead.
This objective is used to optimize PairLogit. Automatically generated object pairs are used for this purpose. These pairs are generated independently for each object group. Use the Group weights file or the GroupWeight column of the Columns description file to change the group importance. In this case, the weight of each generated pair is multiplied by the value of the corresponding group weight.
Usage information See more.
Since CatBoost 1.2.1 YetiRank meaning has been expanded to allow for optimizing specific ranking loss functions by specifying mode loss function parameter. Default YetiRank can now also be referred as mode=Classic.
User-defined parameters
mode
The mode of operation. Either Classic - the traditional YetiRank as described in Winning The Transfer Learning Track of Yahoo!’s Learning To Rank Challenge with YetiRank or a specific ranking loss function to optimize as described in Which Tricks are Important for Learning to Rank? paper. Possible loss function values are DCG, NDCG, MRR, ERR, MAP. Non-Classic modes are supported only on CPU.
Default: Classic
permutations
The number of permutations.
Default: 10
decay
Used only in Classic mode.
The probability of search continuation after reaching the current object.
Default: 0.85
top
Used in all modes except Classic.
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Unlimited by default.
dcg_type
Used in modes DCG and NDCG.
Principle of calculation of *DCG metrics.
Default: Base.
Possible values: Base, Exp.
dcg_denominator
Used in modes DCG and NDCG.
Principle of calculation of the denominator in *DCG metrics.
Default: Position.
Possible values: LogPosition, Position.
noise
Type of noise to add to approxes.
Default: Gumbel.
Possible values: Gumbel, Gauss, No.
noise_power
Power of noise to add (multiplier). Used only for Gauss noise for now.
Default: 1.
num_neighbors
Used in all modes except Classic.
Number of neighbors used in the metric calculation.
Default: 1.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
YetiRankPairwise
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
An approximation of ranking metrics (such as NDCG and PFound). Allows to use ranking metrics for optimization.
The value of this metric can not be calculated. The metric that is written to output data if YetiRank is optimized depends on the range of all N target values () of the dataset:
- — PFound
- — NDCG
This metric gives more accurate results on big datasets compared to YetiRank but it is significantly slower.
This technique is described in the Winning The Transfer Learning Track of Yahoo!’s Learning To Rank Challenge with YetiRank paper.
Note
The object weights are not used to optimize this metric. The group weights are used instead.
This objective is used to optimize PairLogit. Automatically generated object pairs are used for this purpose. These pairs are generated independently for each object group. Use the Group weights file or the GroupWeight column of the Columns description file to change the group importance. In this case, the weight of each generated pair is multiplied by the value of the corresponding group weight.
Usage information See more.
Since CatBoost 1.2.1 YetiRankPairwise meaning has been expanded to allow for optimizing specific ranking loss functions by specifying mode loss function parameter. Default YetiRankPairwise can now also be referred as mode=Classic.
User-defined parameters
mode
The mode of operation. Either Classic - the traditional YetiRankPairwise as described in Winning The Transfer Learning Track of Yahoo!’s Learning To Rank Challenge with YetiRank or a specific ranking loss function to optimize as described in Which Tricks are Important for Learning to Rank? paper. Possible loss function values are DCG, NDCG, MRR, ERR, MAP. Non-Classic modes are supported only on CPU.
Default: Classic
permutations
The number of permutations.
Default: 10
decay
Used only in Classic mode.
The probability of search continuation after reaching the current object.
Default: 0.85
top
Used in all modes except Classic.
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Unlimited by default.
dcg_type
Used in modes DCG and NDCG.
Principle of calculation of *DCG metrics.
Default: Base.
Possible values: Base, Exp.
dcg_denominator
Used in modes DCG and NDCG.
Principle of calculation of the denominator in *DCG metrics.
Default: Position.
Possible values: LogPosition, Position.
noise
Type of noise to add to approxes.
Default: Gumbel.
Possible values: Gumbel, Gauss, No.
noise_power
Power of noise to add (multiplier). Used only for Gauss noise for now.
Default: 1.
num_neighbors
Used in all modes except Classic.
Number of neighbors used in the metric calculation.
Default: 1.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
LambdaMart
Directly optimize the selected metric. The value of the selected metric is written to output data
Refer to the From RankNet to LambdaRank to LambdaMART paper for details.
Usage information See more.
User-defined parameters
metric
The metric that should be optimized.
Default: NDCG
Supported values: DCG, NDCG, MRR, ERR, MAP.
sigma
General sigmoid parameter. See From RankNet to LambdaRank to LambdaMART paper for details.
Default: 1.0
Supported values: Real positive values.
norm
Derivatives should be normalized.
Default: True
Supported values: False, True.
StochasticFilter
Directly optimize the FilteredDCG metric calculated for a pre-defined order of objects for filtration of objects under a fixed ranking. As a result, the FilteredDCG metric can be used for optimization.
is the relevance of an object in the group and the sum is computed over the documents with .
The filtration is defined via the raw formula value:
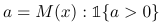
Zeros correspond to filtered instances and ones correspond to the remaining ones.
The ranking is defined by the order of objects in the dataset.
Warning
Sort objects by the column you are interested in before training with this loss function and use the --has-timefor the Command-line version option to avoid further objects reordering.
For optimization, a distribution of filtrations is defined:
- The gradient is estimated via REINFORCE.
Refer to the Learning to Select for a Predefined Ranking paper for calculation details.
Usage information See more.
User-defined parameters
sigma
The scale for multiplying predictions.
Default: 1
num_estimations
The number of gradient samples.
Default: 1
StochasticRank
Directly optimize the selected metric. The value of the selected metric is written to output data
Refer to the StochasticRank: Global Optimization of Scale-Free Discrete Functions paper for details.
Usage information See more.
User-defined parameters
Common parameters:
metric
The metric that should be optimized.
Default: Obligatory parameter
Supported values: DCG, NDCG, PFound.
num_estimations
The number of gradient estimation iterations.
Default: 1
mu
Controls the penalty for coinciding predictions (aka ties).
Default: 0
Metric-specific parameters:
Available if the corresponding metric is set in the metric parameter.
DCG
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
type
Metric calculation principles.
Default: Base.
Possible values: Base, Exp.
denominator
Metric denominator type.
Default: Default: LogPosition.
Possible values: LogPosition, Position.
NDCG
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
type
Metric calculation principles.
Default: Base.
Possible values: Base, Exp.
denominator
Metric denominator type.
Default: LogPosition.
Possible values: LogPosition, Position.
PFound
decay
The probability of search continuation after reaching the current object.
Default: 0.85
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
QueryCrossEntropy
See the QueryCrossEntropy section for more details.
Usage information See more.
User-defined parameters
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
alpha
The coefficient used in quantile-based losses.
Default: 0.95
QueryRMSE
Usage information See more.
User-defined parameters
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
QuerySoftMax
Usage information See more.
User-defined parameters
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
beta
The input scale coefficient.
Default: 1
GroupQuantile
,
where .
Usage information See more.
User-defined parameters
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
PFound
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
See the PFound section for more details
Can't be used for optimization. See more.
User-defined parameters
decay
The probability of search continuation after reaching the current object.
Default: 0.85
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
NDCG
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
See the NDCG section for more details.
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
type
Metric calculation principles.
Default: Base.
Possible values: Base, Exp.
denominator
Metric denominator type.
Default: LogPosition.
Possible values: LogPosition, Position.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
DCG
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
See the NDCG section for more details.
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
type
Metric calculation principles.
Default: Base.
Possible values: Base, Exp.
denominator
Metric denominator type.
Default: LogPosition.
Possible values: LogPosition, Position.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
FilteredDCG
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
See the FilteredDCG section for more details.
Can't be used for optimization. See more.
User-defined parameters
type
Metric calculation principles.
Default: Base.
Possible values: Base, Exp.
denominator
Metric denominator type.
Default: LogPosition.
Possible values: LogPosition, Position.
QueryAverage
Represents the average value of the label values for objects with the defined top label values.
See the QueryAverage section for more details.
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: This parameter is obligatory (the default value is not defined).
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: true
PrecisionAt
The calculation of this function consists of the following steps:
-
The objects are sorted in descending order of predicted relevancies ()
-
The metric is calculated as follows:
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
border
The label value border. If the value is strictly greater than this threshold, it is considered a positive class. Otherwise it is considered a negative class.
Default: 0
RecallAt
The calculation of this function consists of the following steps:
-
The objects are sorted in descending order of predicted relevancies ()
-
The metric is calculated as follows:
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
border
The label value border. If the value is strictly greater than this threshold, it is considered a positive class. Otherwise it is considered a negative class.
Default: 0
MAP
-
The objectsare sorted in descending order of predicted relevancies ()
-
The metric is calculated as follows:
- is the number of groups
The value is calculated individually for each j-th group.
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
border
The label value border. If the value is strictly greater than this threshold, it is considered a positive class. Otherwise it is considered a negative class.
Default: 0
ERR
Targets should be from the range [0, 1].
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
MRR
, where refers to the rank position of the first relevant document for the q-th query.
Can't be used for optimization. See more.
User-defined parameters
top
The number of top samples in a group that are used to calculate the ranking metric. Top samples are either the samples with the largest approx values or the ones with the lowest target values if approx values are the same.
Default: –1 (all label values are used).
border
The label value border. If the value is strictly greater than this threshold, it is considered a positive class. Otherwise it is considered a negative class.
Default: 0
AUC
The calculation of this metric is disabled by default for the training dataset to speed up the training. Use the hints=skip_train~false parameter to enable the calculation.
The type of AUC. Defines the metric calculation principles.
Classic type
The sum is calculated on all pairs of objects such that:
Refer to the Wikipedia article for details.
If the target type is not binary, then every object with target value and weight is replaced with two objects for the metric calculation:
- with weight and target value 1
- with weight and target value 0.
Target values must be in the range [0; 1].
Ranking type
The sum is calculated on all pairs of objects such that:
Can't be used for optimization. See more.
User-defined parameters
type
The type of AUC. Defines the metrics calculation principles.
Default: Classic.
Possible values: Classic, Ranking.
Examples: AUC:type=Classic, AUC:type=Ranking.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: False for Classic type, True for Ranking type.
Examples: AUC:type=Ranking;use_weights=False.
QueryAUC
Classic type
The sum is calculated on all pairs of objects such that:
Refer to the Wikipedia article for details.
If the target type is not binary, then every object with target value and weight is replaced with two objects for the metric calculation:
- with weight and target value 1
- with weight and target value 0.
Target values must be in the range [0; 1].
Ranking type
The sum is calculated on all pairs of objects such that:
Can't be used for optimization. See more.
User-defined parameters
type
The type of QueryAUC. Defines the metric calculation principles.
Default: Ranking.
Possible values: Classic, Ranking.
Examples: QueryAUC:type=Classic, QueryAUC:type=Ranking.
use_weights
Use object/group weights to calculate metrics if the specified value is true
and set all weights to 1
regardless of the input data if the specified value is false
.
Default: False.
Examples: QueryAUC:type=Ranking;use_weights=False.
Used for optimization
| Name | Optimization | GPU Support |
|---|---|---|
| PairLogit | + | + |
| PairLogitPairwise | + | + |
| PairAccuracy | - | - |
| YetiRank | + | + (but only Classic mode) |
| YetiRankPairwise | + | + (but only Classic mode) |
| LambdaMart | + | - |
| StochasticFilter | + | - |
| StochasticRank | + | - |
| QueryCrossEntropy | + | + |
| QueryRMSE | + | + |
| QuerySoftMax | + | + |
| GroupQuantile | + | - |
| PFound | - | - |
| NDCG | - | - |
| DCG | - | - |
| FilteredDCG | - | - |
| QueryAverage | - | - |
| PrecisionAt | - | - |
| RecallAt | - | - |
| MAP | - | - |
| ERR | - | - |
| MRR | - | - |
| AUC | - | - |
| QueryAUC | - | - |