compare
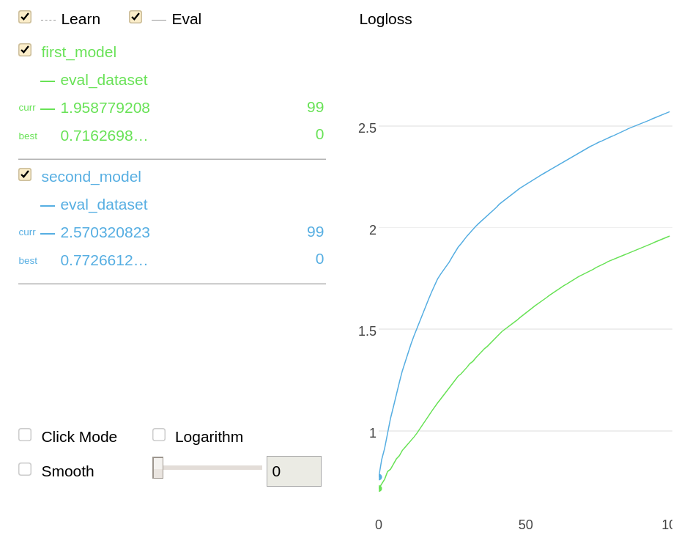
Draw train and evaluation metrics in Jupyter Notebook for two trained models.
Method call format
compare(model,
data=None,
metrics=None,
ntree_start=0,
ntree_end=0,
eval_period=1,
thread_count=-1,
tmp_dir=None,
log_cout=sys.stdout,
log_cerr=sys.stderr)
Parameters
Parameter: model
Possible types: CatBoost Model
Description
The CatBoost model to compare with.
Default value
Required parameter
Parameter: metricslist of strings
The list of metrics to be calculated.
Supported metrics
For example, if the AUC and Logloss metrics should be calculated, use the following construction:
['Logloss', 'AUC']
Required parameter
Parameter: data
Possible types: catboost.Pool
Description
A file or matrix with the input dataset, on which the compared metric values should be calculated.
Default value
Required parameter
Parameter: ntree_start
Possible types: int
Description
To reduce the number of trees to use when the model is applied or the metrics are calculated, set the range of the tree indices to[ntree_start; ntree_end) and the eval_period parameter to k to calculate metrics on every k-th iteration.
This parameter defines the index of the first tree to be used when applying the model or calculating the metrics (the inclusive left border of the range). Indices are zero-based.
Default value
0
Parameter: ntree_end
Possible types: int
Description
To reduce the number of trees to use when the model is applied or the metrics are calculated, set the range of the tree indices to[ntree_start; ntree_end) and the eval_period parameter to k to calculate metrics on every k-th iteration.
This parameter defines the index of the first tree not to be used when applying the model or calculating the metrics (the exclusive right border of the range). Indices are zero-based.
Default value
0 (the index of the last tree to use equals to the number of trees in the
model minus one)
Parameter: eval_period
Possible types: int
Description
To reduce the number of trees to use when the model is applied or the metrics are calculated, set the range of the tree indices to[ntree_start; ntree_end) and the eval_period parameter to k to calculate metrics on every k-th iteration.
This parameter defines the step to iterate over the range [ntree_start; ntree_end). For example, let's assume that the following parameter values are set:
ntree_startis set 0ntree_endis set to N (the total tree count)eval_periodis set to 2
In this case, the metrics are calculated for the following tree ranges: [0, 2), [0, 4), ... , [0, N)
Default value
1 (the trees are applied sequentially: the first tree, then the first two
trees, etc.)
Parameter: thread_countint
The number of threads to use.
Optimizes the speed of execution. This parameter doesn't affect results.
-1 (the number of threads is equal to the number of processor cores)
Parameter: tmp_dir
Possible types: String
Description
The name of the temporary directory for intermediate results.
Default value
None (the name is generated)
log_cout
Output stream or callback for logging.
Possible types
- callable Python object
- python object providing the
write()method
Default value
sys.stdout
log_cerr
Error stream or callback for logging.
Possible types
- callable Python object
- python object providing the
write()method
Default value
sys.stderr
Examples
from catboost import Pool, CatBoostClassifier
train_data = [[0, 3],
[4, 1],
[8, 1],
[9, 1]]
train_labels = [0, 0, 1, 1]
eval_data = [[1, 3],
[4, 2],
[8, 2],
[8, 3]]
eval_labels = [1, 0, 0, 1]
train_dataset = Pool(train_data, train_labels)
eval_dataset = Pool(eval_data, eval_labels)
model1 = CatBoostClassifier(iterations=100, learning_rate=0.1)
model1.fit(train_dataset, verbose=False)
model2 = CatBoostClassifier(iterations=100, learning_rate=0.3)
model2.fit(train_dataset, verbose=False)
model1.compare(model2, eval_dataset, ['Logloss'])
The following is a chart plotted with Jupyter Notebook for the given example.