Cloudflare's Protection Against Bots Employs CatBoost
Bot-powered credential stuffing is a scourge on the modern Internet. These attacks attempt to log into and take over a user's account by assaulting password forms with a barrage of dictionary words and previously stolen account credentials, with the aim of performing fraudulent transactions, stealing sensitive data, and compromising personal information.
At Cloudflare we've built a suite of technologies to combat bots, many of them grounded in Machine Learning. ML is a hot topic these days, but the literature tends to focus on improving the core technology — and not how these learning machines are incorporated into real-world organizations.
Given how much experience we have with ML (which we employ for many security and performance products, in addition to bot management), we wanted to share some lessons learned with regard to how this technology manifests in actual products.

There tend to be three stages every company goes through in the life cycle of infusing machine learning into their DNA. They are:
- Business Intelligence
- Standalone Machine Learning
- Machine Learning Productization
These concepts are a little abstract — so let's walk through how they might apply to a tangible field we all know and love: dental insurance.
Business Intelligence
Many companies already have some kind of business intelligence: an ability to sort, search, filter and perform rudimentary labeling on a large corpus of data. Business Intelligence is not machine learning per se, but it can serve as its foundation.
- Imagine your friendly neighborhood dental insurance company, ACMEDental, regularly receives dental claims. For each claim, a trained insurance professional evaluates the incoming X-rays to confirm the dentist’s diagnosis — and marks the claim as accurate or inaccurate.
- On the surface, this data provides actionable intelligence: an uptick in incorrect diagnoses from a particular dentist or region might warrant further investigation. But this data can be used for something much more interesting.
Standalone Machine Learning
The key to training a machine learning model is to compile a labeled data set: raw data paired with a descriptive label that tells the computer what it's looking at. These data sets are often a natural byproduct of Business Intelligence, as we're about to see.
- Some ingenious engineers at ACMEDental notice that through their day-to-day operations they've compiled a large repository of X-rays, labeled either ‘accurate’ or ‘inaccurate’.
- With several thousand labeled X-rays in hand, they decide to train a machine learning algorithm that can judge X-rays automatically. They use one of several open-source tools to do this using image recognition, yielding an ML algorithm that can scan an X-ray and categorize the claim with impressive accuracy.
Machine Learning Productization
Once a functioning algorithm is in-hand, there is the matter of turning it into a product. This generally involves collaboration between engineering, product design, and ultimately, business development and sales.
- ACMEDental finds its new ML algorithm to be so effective that its product managers decide to offer it for license to X-ray machine manufacturers. By integrating the ACMEDental algorithm, a dentist could accelerate their workflow and reduce the likelihood of incorrect diagnoses. The machine could also communicate with the insurance company for instant claim approvals.
- After productizing the algorithm for integration, ACMEDental's business development team reaches out to manufacturers like Samsung to pursue a partnership.
- The new X-ray machines, enhanced by ACMEDental's algorithm, prove to be a hit on the market — allowing dentists to offload routine diagnostics to their assistants.
With this framework in mind let's explore how we're leveraging machine learning at Cloudflare.
To inform our machine learning models, we rely on data from the 13 million domains on Cloudflare's network, which sees more than 660 billion requests per day serving more than 2.8 billion people per month. We employ this huge volume of data to address one of the most urgent security threats on the web: bot attacks.

Business Intelligence
We recently analyzed one day's worth of requests from across all of Cloudflare's 13 million domains — 660 billion requests — and labeled each potential attack with a ‘bot score’ ranging from 0 to 100. Cloudflare already has an extensive array of tools which help inform this score, but in principle, we could manually label each datapoint as ‘bot’ or ‘not bot’, similar to the dentist example above.
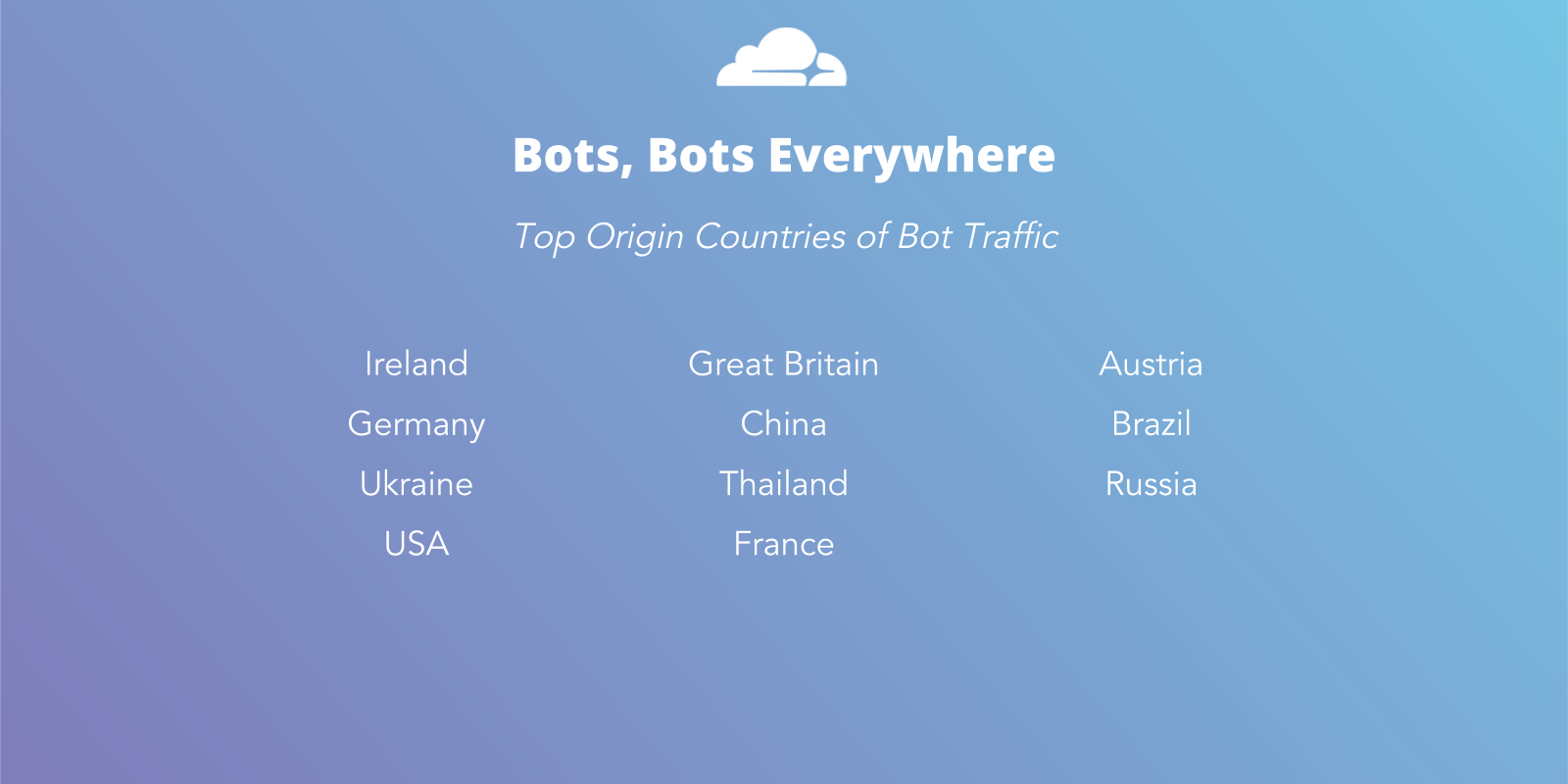
One initial takeaway from our analysis was the geographical breakdown of attacks. Rudimentary bot-protection tools rely on blocking IP addresses from countries commonly associated with hostile traffic. But when we ranked the origin of bots across our network, it was obvious that this approach was untenable as most attacks originate from countries with huge volumes of legitimate traffic. A more sophisticated solution allows us to protect against bots without affecting real users.
Standalone Machine Learning
Having compiled a large dataset sampled from Cloudflare's network, our team of ML experts developed a state-of-the-art model to predict automated credential stuffing and other bot attacks.
Training: We started with a trillion requests (compiled over multiple days) in our training set, each of them labeled with the aforementioned bot score — and analyzed their features on a CPU/GPU cluster to recognize trends in malicious traffic. We used CatBoost, a gradient boosting library similar to XGBoost.
Validation: Though we perform hundreds of independent validations tests, the ultimate validation is how many login attempts have been challenged with a Captcha, versus how many have solved a Captcha (a solved Captcha likely indicates a false positive).
Over the course of a week, we deployed our solution to 95 websites with WordPress login pages and found that we issued more than 660,000 challenges, of which only 0.32% were solved — meaning our algorithm detected bots with a 99.68% rate of True Positives.
While this work is just beginning, WordPress represents 32.5% of all websites worldwide, so this is a very meaningful step forward. Meanwhile, we found that more than 80% of requests to WordPress login pages are Credential Stuffing attacks, underscoring just how prevalent these attacks are.
Machine Learning Productization
Deployment: Once we became sufficiently confident in the accuracy of our algorithm, we deployed it as one of the many security features constantly running across the 165 server facilities worldwide that comprise Cloudflare's network edge. Today, it evaluates over 660 billion requests per day — learning and improving from each additional attack observed on the network.
But it wasn't long before we found ourselves asking: is knowing and stopping credential stuffing attacks in real-time enough? Can we do more?
We used our existing data and began thinking of how to develop an algorithm to predict which companies will be attacked next. This would allow us to proactively warn companies before an attack occurs and prepare them for the worst case scenario, even if they aren't currently on Cloudflare's network.
Training: We trained our Machine Learning Model with firmographic information like industry type, number of employees, and the revenue amount to predict the percentage of login attacks.
Results: Amongst the many interesting findings is that smaller companies have a higher fraction of attacks. Intuitively, this makes sense because the opportunistic attack traffic scanning the Internet is equal on all pages while the human traffic on popular sites outweighs the bot attacks. Thus even though small companies represent a smaller traffic volume, they're the most vulnerable to attack.
Do these findings only affect the 13 million Cloudflare websites with 2.8 billion visitors across 237 countries that we had in our model? Likely not. That means Cloudflare can begin thinking about helping all companies by proactively anticipating attacks based on their unique risk profile.
Machine learning has been crucial to the development of our next generation of products, and we've only scratched the surface. We hope that this post is useful as you map out the trajectory of ML in your own organization: your road will be different, but hopefully you will see some familiar milestones along the way.
Cloudflare is actively developing its machine learning capabilities — if you're interested in joining us or partnering with us on our mission please get in touch.
This is a repost of Nikon Rasumov's blog post at Cloudflare: ‘Stop the Bots: Practical Lessons in Machine Learning.’