Extremely fast learning on GPU has arrived!
We're excited to announce the CatBoost 0.3 release with GPU support. It's incredibly fast!
- Training on a single GPU outperforms CPU training up to 40x times on large datasets.
- CatBoost efficiently supports multi-card per unit configuration. A configuration with a single server with 8 GPUs outperforms a configuration with hundreds of CPUs by execution time.
- We compared our GPU implementation with competitors. And it is 2 times faster then LightGBM and more then 20 times faster then XGBoost.
- Finally CatBoost GPU Python wrapper is very easy to use.
To prove our words we prepared a set of benchmarks below. There we compared:
- CPU vs GPU training speed of CatBoost
- GPU training performance of CatBoost, XGBoost and LightGBM
CatBoost CPU vs. GPU
Configuration: dual-socket server with 2 Intel Xeon CPU (E5-2650v2, 2.60GHz) and 256GB RAM
Methodology: CatBoost was started in 32 threads (equal to number of logical cores). GPU implementation was run on several servers with different GPU types. Our GPU implementation doesn’t require multi-core server for high performance, so different CPU and machines should not significantly affect GPU benchmark results.
Dataset #1: Criteo (36M samples, 26 categorical, 13 numerical features) to benchmark our categorical features support.
| Type | 128 bins (sec) |
|---|---|
| CPU | 1060 |
| K40 | 373 |
| GTX 1080Ti (11GB) | 301 |
| 2xGTX 1080 (8GB) | 285 |
| P40 | 123 |
| P100-PCI | 82 |
| V100-PCI | 69.8 |
As you can see CatBoost GPU version significantly outperforms CPU training time even on old generation GPU (Tesla K40) and gains impressive x15 speed up on flagship NVIDIA V100 card.
Dataset #2: Epsilon (400K samples, 2000 features) to benchmark our performance on dense numerical dataset. In the table we report training time for different levels of binarizations: default 128 bins and 32 bins which is often sufficient. Note that Epsilon dataset has not enough samples to fully utilize GPU, and with bigger datasets we observe up to 40x speed ups.
| Type | 128 bins (sec) | 32 bins (sec) |
|---|---|---|
| CPU | 713 | 653 |
| K40 | 547 | 248 |
| GTX 1080 (8GB) | 194 | 120 |
| P40 | 162 | 91 |
| GTX 1080Ti (11GB) | 145 | 88 |
| P100-PCI | 127 | 70 |
| V100-PCI | 77 | 49 |
GPU training performance: comparison with baselines
Configuration: NVIDIA P100 accelerator, dual-core Intel Xeon E5-2660 CPU and 128GB RAM
Dataset: Epsilon (400K samples for train, 100K samples for test).
Libraries: CatBoost, LightGBM, XGBoost (we use histogram-based version, exact version is very slow)
Methodology: We measured mean tree construction time one can achieve without using feature subsampling and/or bagging. For XGBoost and CatBoost we use default tree depth equal to 6, for LightGBM we set leafs count to 64 to have more comparable results. We set bin to 15 for all 3 methods. Such bin count gives the best performance and the lowest memory usage for LightGBM and CatBoost (128-255 bin count usually leads both algorithms to run 2-4 times slower). For XGBoost we could use even smaller bin count but performance gains compared to 15 bins are too small to account for. All algorithms were run with 16 threads, which is equal to hardware core count.
By default CatBoost uses bias-fighting scheme . This scheme is by design 2-3 times slower then classical boosting approach. CatBoost GPU implementation contains a mode based on classic scheme for those who need best training performance. We used classic scheme mode in our benchmark.
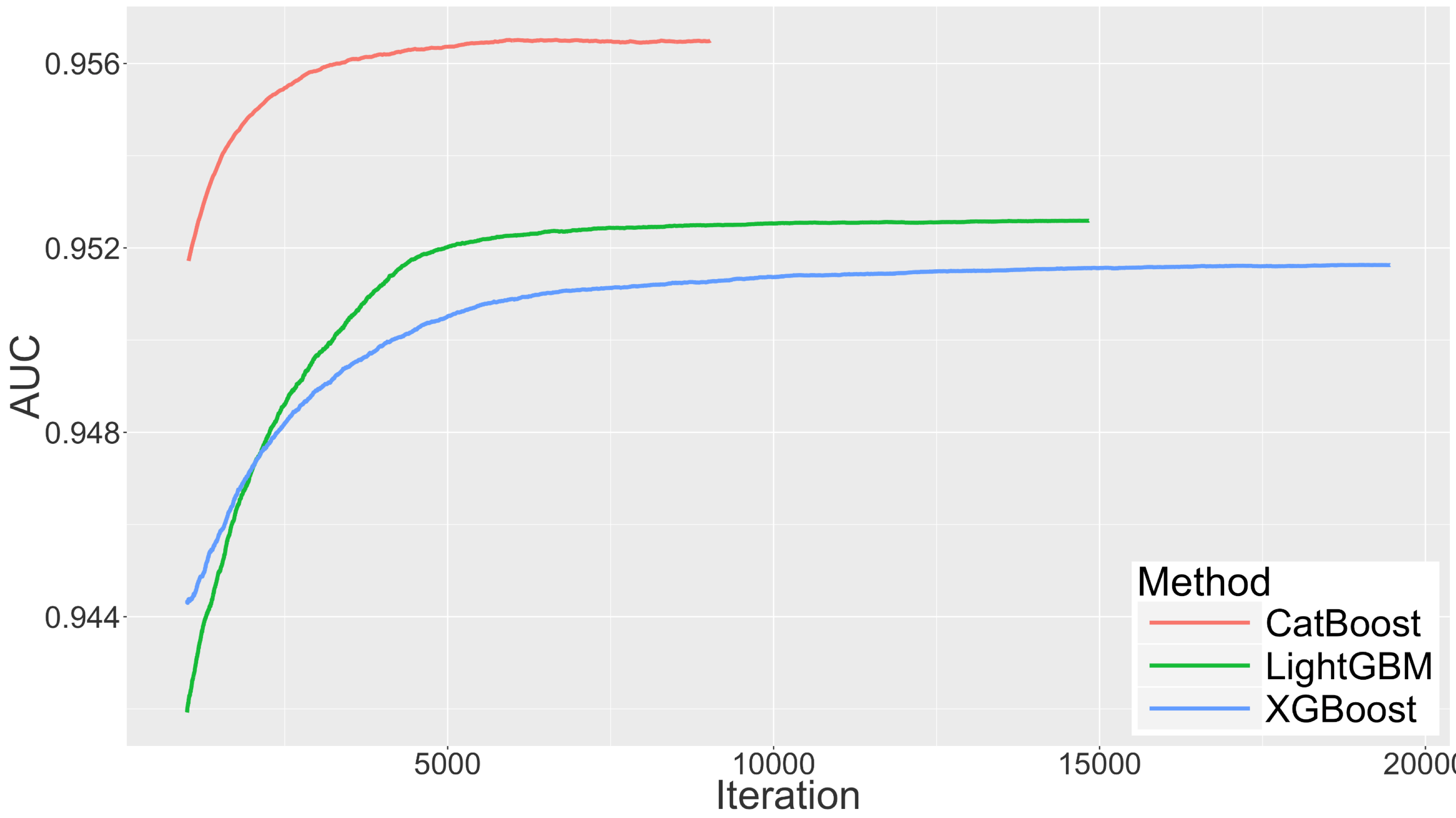
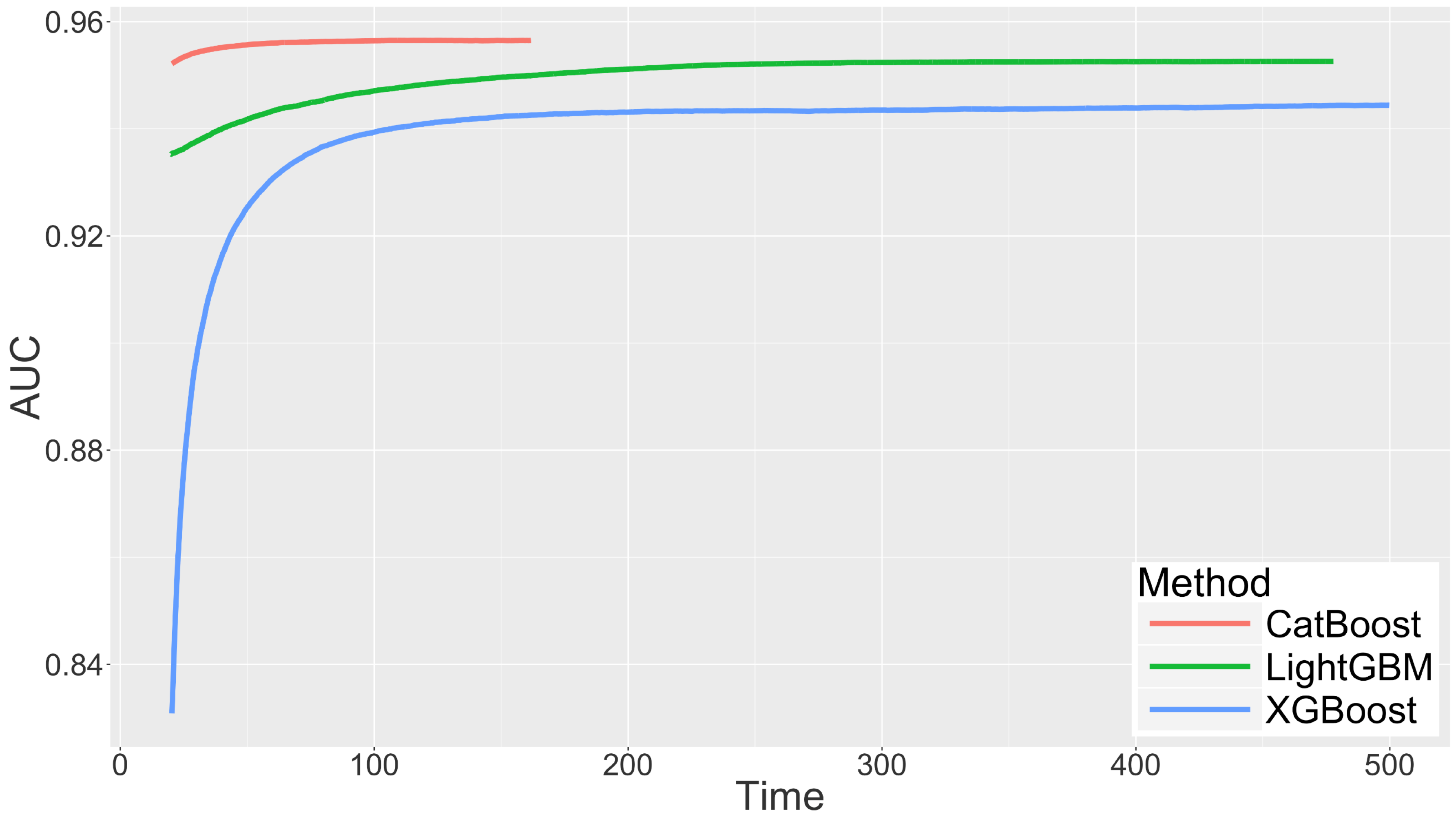
We set such learning rate that algorithms start to overfit approximately after 8000 rounds (learning curves are displayed at figure above, quality of obtained models differs by approximately 0.5%). We measured time to train ensembles of 8000 trees. Mean tree construction time for CatBoost was 17.9ms, for XGBoost 488ms, for LightGBM 40ms. As you can see CatBoost 2 times faster then LightGBM and 20 times faster then XGBoost.
Don’t forget to examine CatBoost GPU documentation. As usual, you could find all the code on GitHub.
Any contribution and issues are appreciated!